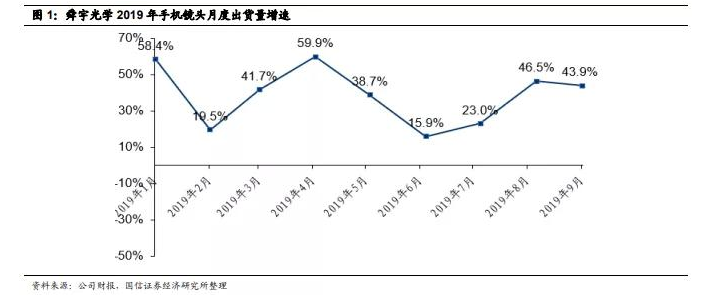
- 首頁
-
産品中心

AS/RS系統

AS/RS系統

AS/RS系統-有軌巷道堆垛機(單深)

AS/RS系統-有軌巷道堆垛機(雙深)

AS/RS系統-有軌巷道堆垛機(多(duō)深)

AS/RS系統-托盤輸送設備

AS/RS系統-RGV設備

AS/RS系統-環穿設備

AS/RS系統-托盤提升機

箱式輸送系統-鋁合金結構系列

箱式輸送系統-鋁合金結構系列

箱式輸送系統-鋁合金結構系列

箱式輸送系統-鋁合金結構系列

箱式輸送系統-鋁合金結構系列

箱式輸送系統-鋁合金結構系列

箱式輸送系統-碳鋼結構系列

箱式輸送系統-碳鋼結構系列

箱式輸送系統-碳鋼結構系列

箱式輸送系統-碳鋼結構系列

螺旋提升機

垂直提升機
-
軟件中心
 了(le)解更多(duō)
了(le)解更多(duō)蜂鳥中台是伍強十年來(lái)物(wù)流實踐的(de)結晶,其重要理(lǐ)念是通(tōng)過WCS實現WMS與設備的(de)無關性,目前與世界上很多(duō)著名的(de)WMS軟件成功對(duì)接。
 了(le)解更多(duō)
了(le)解更多(duō)結合用(yòng)戶的(de)深度業務邏輯與三維可(kě)視化(huà)技術,對(duì)現實世界進行數字化(huà)建模,依靠大(dà)數據和(hé)人(rén)工智能等技術,對(duì)未來(lái)各種事件進行模拟。
 了(le)解更多(duō)
了(le)解更多(duō)AutoWMS系統具有多(duō)倉庫管理(lǐ)、多(duō)貨主管理(lǐ)、批次管理(lǐ)、波次管理(lǐ)、績效管理(lǐ)等多(duō)功能,更多(duō)體現出作爲國際化(huà)的(de)軟件系統的(de)一面。
-
行業方案
 了(le)解更多(duō)
了(le)解更多(duō)爲您提供不同場(chǎng)景的(de)個(gè)性化(huà)解決方案,助力企業打造高(gāo)自動化(huà)、高(gāo)智能化(huà)、高(gāo)效率、高(gāo)标準的(de)現代醫藥物(wù)流中心。
 了(le)解更多(duō)
了(le)解更多(duō)爲您提供一站式電商全路鏈物(wù)流解決方案,提高(gāo)了(le)物(wù)流中心柔性化(huà)設計、訂單履約速度和(hé)準确性、自動化(huà)系統的(de)訂單完成速度可(kě)以比人(rén)工系統快(kuài)N倍……
 了(le)解更多(duō)
了(le)解更多(duō)半導體設備訂單式的(de)生産特性對(duì)生産物(wù)流配送提出了(le)更高(gāo)的(de)要求,物(wù)流中心需要按照(zhào)訂單進行備料并确保能快(kuài)速響應生産節拍(pāi),及時(shí)供應到産線。
 了(le)解更多(duō)
了(le)解更多(duō)爲美(měi)妝公司量身打造一流的(de)現代物(wù)流中心,以解決其快(kuài)速增長(cháng)的(de)銷售量帶來(lái)的(de)供應鏈運營、分(fēn)揀、物(wù)流等問題……
 了(le)解更多(duō)
了(le)解更多(duō)爲您提供光(guāng)伏能源的(de)整體解決方案,實現靈活搬運,滿足人(rén)機混行場(chǎng)景;大(dà)大(dà)減少人(rén)力投入,降低開發難度,提高(gāo)整機運行效率。
 了(le)解更多(duō)
了(le)解更多(duō)爲您提供面向制造業的(de)一站式數智化(huà)解決方案,減少存儲空間占用(yòng)量,以便釋放容量、縮短流程時(shí)間、降低中斷風險并提高(gāo)安全性,同時(shí)降低生産和(hé)配送成本。
 了(le)解更多(duō)
了(le)解更多(duō)爲您提供可(kě)同時(shí)服務多(duō)個(gè)用(yòng)戶,實現資源利用(yòng)最大(dà)化(huà)的(de)3PL行業解決方案,大(dà)大(dà)提高(gāo)庫存周轉與運營效率、訂單履約速度和(hé)準确性。
 了(le)解更多(duō)
了(le)解更多(duō)加快(kuài)了(le)食品流通(tōng),确保冷(lěng)鏈不斷鏈的(de)溫度條件,保證了(le)食品安全;應用(yòng)自動化(huà)無人(rén)立體倉庫,也(yě)确保了(le)食品存取的(de)安全、環保、高(gāo)效。
-
無憂服務
-
新聞中心
-
關于我們





























400-010-3808
收藏我們